At any scale, an end-to-end monitoring solution for your infrastructure and workload is essential because:
You need to make sure your resources are well used and know when to scale up/down.
You need to make sure the applications are running in good health and are performant.
You need to know any system hiccups and be able to take actions when disaster happens.
When in comes to Kubernetes, monitoring is very different from traditional infrastructure and a lot more complicated:
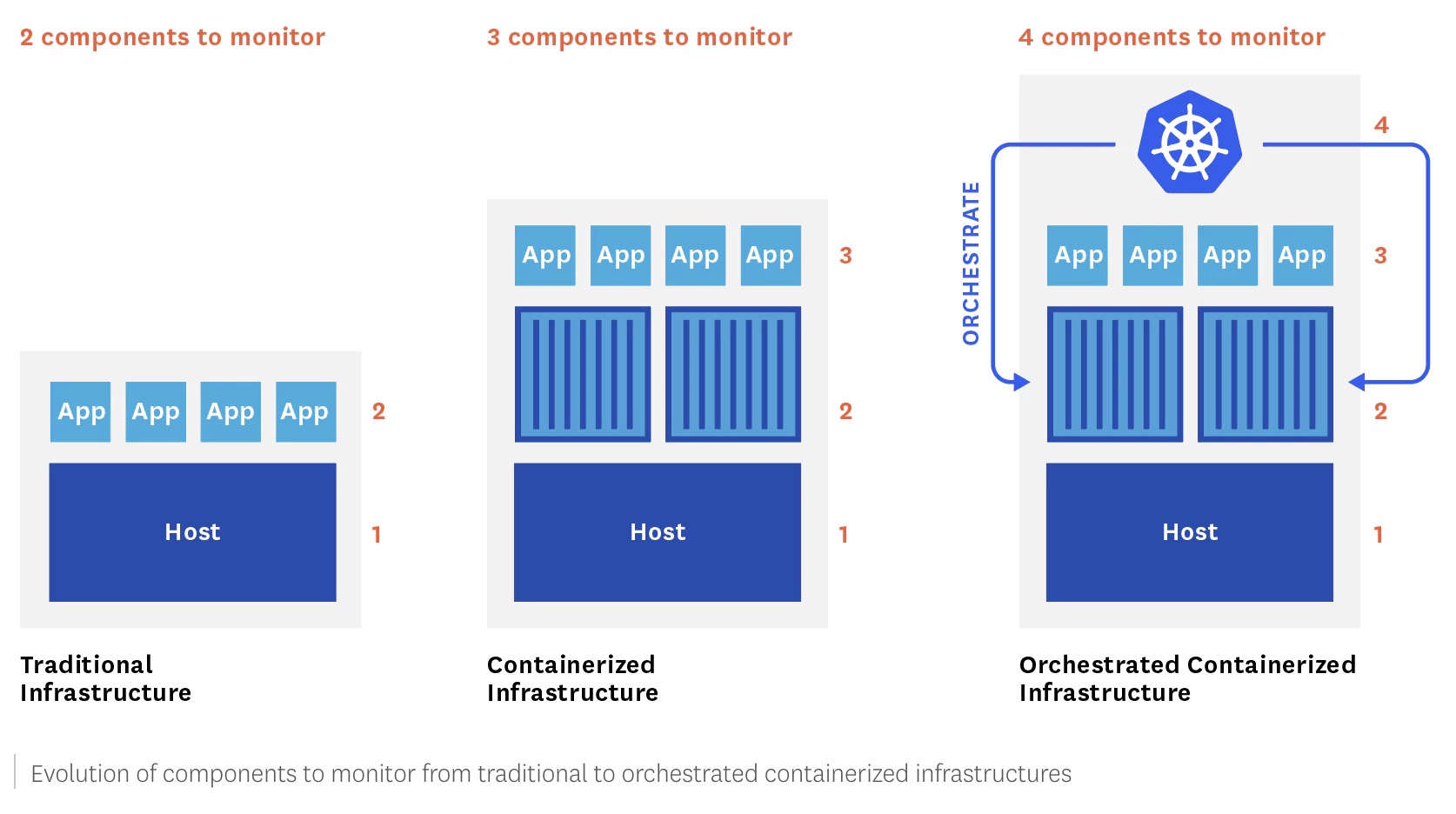Kubernetes has brought up the era of Orchestrated Containerized Infrastructure, but it also means we have more components to monitor:
The nodes on which Kubernetes and its workload are running.
The containers
The containerized applications
The Orchestration tool (Kubernetes) itself.
Where are metrics coming from
As discussed in above section, we have 4 components to monitor and for each of them we need to know where can we get the metric for them.
Our Solution: Prometheus Operator
It would be nice if we can use some existing tool other than hand-making a monitoring system from scratch, and luckily we have Prometheus Operator by CoreOS. Prometheus operator creates, configures, and manages Prometheus monitoring instances and automatically generates monitoring target configurations based on Kubernetes label queries.
The above graph shows a desired state of a prometheus deployment, the service monitor defines what services to monitor by prometheus using label selectors, the same way as a service defines what pods to expose by label selectors.
The host/nodes metrics
Prometheus uses node_exporter to collect nodes CPU, memory and disk usage and much more, we deploy node_exporter as deamonset so it runs on each nodes in the cluster.
The containers
The containers metrics are collected from kubelet, which is the Kubernetes component that manages pods and containers.
The containerized applications
To monitor your application data, there are two ways of doing it
pull - you instrument your application using Prometheus’s client and provide metrics endpoints for Prometheus’s to scrape.
push - you use Prometheus Pushgateway to push metrics to an intermediary job which Prometheus can scrape.
All metrics data for your applications can be monitored via ServiceMonitor, you just need to make sure you define the right path and port.
The Kubernetes cluster
Metrics about the cluster state are exposed using kube-state-metrics, which is a simple service that listens to the Kubernetes API server and generates metrics about the state of the objects, e.g. deployments, pods, nodes and etc.
Deploy the Prometheus Operator
You can find a ready-to-go prometheus operator deployment here.
In this post, I’ll go through the important pieces of the puzzle.
The node_exporter for nodes metrics
Node exporter runs on each node, thus we can deploy them via DaemonSet.
In the above yaml file, we specified a service account for node exporter and bind it with a cluster role with the permission to create tokenreviews. We then deploy the node exporter pods via DaemonSet and expose a headless service for these pods and specify a ServiceMonitor, which will scrape the metrics from the service and send to prometheus.
The kube-state-metrics for Kubernetes Cluster metrics
We can collect Kubernetes cluster metrics via kube-state-metrics, which is the new official tool provided by the Kubernetes community that outputs prometheus format of metrics for monitoring purpose. The kube-state-metrics talks to kube-api-server to generate metrics about the state of objects, so different from node exporter, we don’t run it on every node as DaemonSet, instead we only deploy it as a deployment with 1 replicaset.
In the above yaml definition, the same as the node exporter, we create roles with the minimum access requirement and bind them to the service account we created specifically for the kube-state-metrics service. We will then deploy it via Deployment, expose a headless service and define a ServiceMonitor to scape the metrics and send to Prometheus.
The kubelet exports prometheus format metrics at the endpoint /metrics/cadvisor. Please note that the kubelet is not self-hosted by Kubernetes, thus there’s actually no such service to select by the selector for the ServiceMonitor. Therefore the Prometheus Operator implements a functionality to synchronize the kubelets into an Endpoints object. To make use of that functionality the –kubelet-service argument must be passed to the Prometheus Operator when running it, it will then emulate as it there’s a kubelet service running inside the Kubernetes cluster.
Aside from kubelet, the other Kubernetes components are self-hosted mostly. Thus to collect metrics from them, we simply need to expose them with a headless service and define ServiceMonitors for them. Please note that for API server, a kubernetes service is already exposed in the default namespace, so there is no extra action to take to discover the API server.
Up to this point, I think you should already understand how promethus works. In order to monitor a application, you need to export an endpoint at a defined path, using which the ServiceMonitor can scape prometheus format metrics. You will then need to export the service for the application and define a ServiceMonitor to do the scraping job.
How it looks for Prometheus Operator deployment
After you deploy Prometheus Operator, give the system sometime to create the objects, if you encounter an error for the first, just re-run kubelet apply again. We can check the status of the deployment by running:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
kubectl get -n monitoring pods
NAME READY STATUS RESTARTS AGE alertmanager-main-0 2/2 Running 0 3d alertmanager-main-1 2/2 Running 0 3d alertmanager-main-2 2/2 Running 0 3d grafana-6fc9dff66-g8jf4 1/1 Running 0 3d kube-state-metrics-697b8b58fb-5svg9 4/4 Running 0 3d node-exporter-85cmz 2/2 Running 0 3d node-exporter-9498f 2/2 Running 0 3d node-exporter-hx6fw 2/2 Running 0 3d node-exporter-swbpq 2/2 Running 0 3d node-exporter-zd2ts 2/2 Running 0 3d prometheus-k8s-0 2/2 Running 1 3d prometheus-k8s-1 2/2 Running 1 3d prometheus-operator-7dd7b4f478-hvd9s 1/1 Running 0 3d
You should have alertmanager, grafana, node-exporter, promethus and prometheus-operator running as expected.
Predefined Dashboards
After your Prometheus cluster is up and running, you can notice that a pod of Grafana is up and running, the user name and password is both admin.
Using datasource from the Prometheus cluster, there are a few pre-defined dashboards already showing your cluster/nodes/pods status.
Summary
Prometheus Operator provides an easy end-to-end monitoring system for you Kubernetes cluster. It does most of the heavy lift and has a lot of pre-defined metrics for different components, as well the dashboards to visualize the mtrics and the alarms on abnormality. To extend it for monitoring any of your containerized application metrics, as a user, the majority of your work will be:
Write code using Prometheus SDK in your application to expose your desired metrics via an endpoint.
Expose your application with a Service, you can make the Service headless if you don’t want it to be accessible from out of the Cluster.
Define ServiceMonitor to scape the your metrics from the service.
Define Grafana dashboard to visualize your metrics from promethus datasource.


